
Microsoft has released VibeVoice-Realtime-0.5B, a real time text to speech model that works with streaming text input and long form speech output, aimed at agent style applications and live data narration. The model can start producing audible speech in about 300 ms, which is critical when a language model is still generating the rest of …
Continue reading Microsoft AI Releases VibeVoice-Realtime: A Lightweight Real‑Time Text-to-Speech Model Supporting Streaming Text Input and Robust Long-Form Speech Generation
Category:AI Research
How We Learn Step-Level Rewards from Preferences to Solve Sparse-Reward Environments Using Online Process Reward Learning

In this tutorial, we explore Online Process Reward Learning (OPRL) and demonstrate how we can learn dense, step-level reward signals from trajectory preferences to solve sparse-reward reinforcement learning tasks. We walk through each component, from the maze environment and reward-model network to preference generation, training loops, and evaluation, while observing how the agent gradually improves …
Continue reading How We Learn Step-Level Rewards from Preferences to Solve Sparse-Reward Environments Using Online Process Reward Learning
NVIDIA and Mistral AI Bring 10x Faster Inference for the Mistral 3 Family on GB200 NVL72 GPU Systems
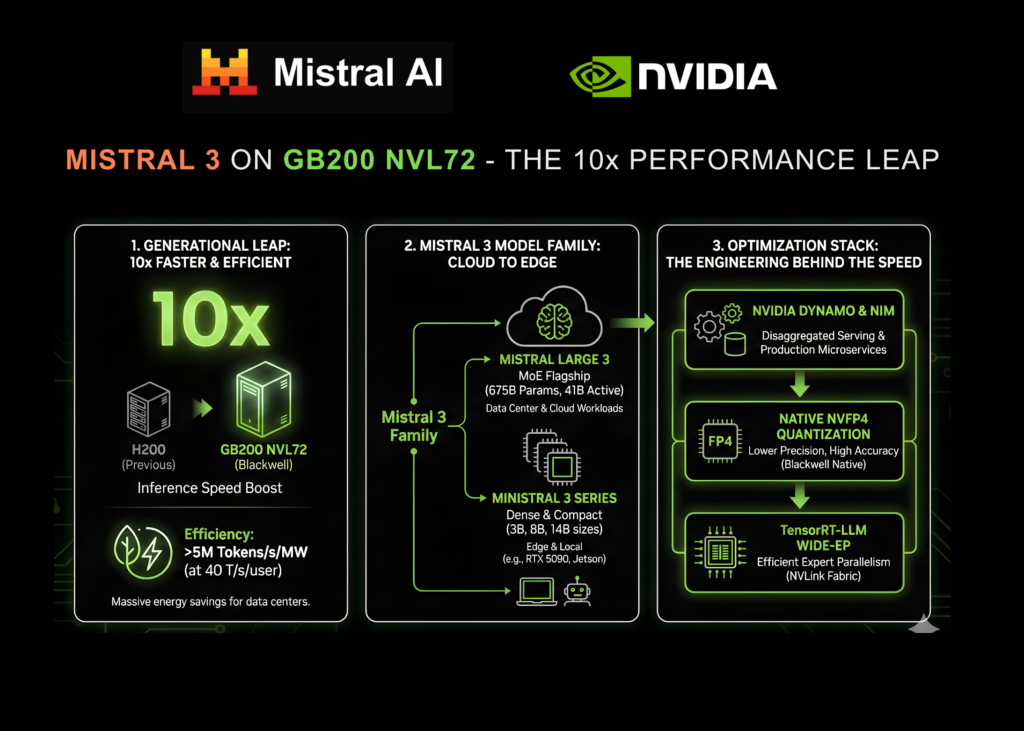
NVIDIA announced today a significant expansion of its strategic collaboration with Mistral AI. This partnership coincides with the release of the new Mistral 3 frontier open model family, marking a pivotal moment where hardware acceleration and open-source model architecture have converged to redefine performance benchmarks. This collaboration is a massive leap in inference speed: the …
Continue reading NVIDIA and Mistral AI Bring 10x Faster Inference for the Mistral 3 Family on GB200 NVL72 GPU Systems
How to Build an Adaptive Meta-Reasoning Agent That Dynamically Chooses Between Fast, Deep, and Tool-Based Thinking Strategies

We begin this tutorial by building a meta-reasoning agent that decides how to think before it thinks. Instead of applying the same reasoning process for every query, we design a system that evaluates complexity, chooses between fast heuristics, deep chain-of-thought reasoning, or tool-based computation, and then adapts its behaviour in real time. By examining each …
Continue reading How to Build an Adaptive Meta-Reasoning Agent That Dynamically Chooses Between Fast, Deep, and Tool-Based Thinking Strategies
How to Build a Meta-Cognitive AI Agent That Dynamically Adjusts Its Own Reasoning Depth for Efficient Problem Solving

In this tutorial, we build an advanced meta-cognitive control agent that learns how to regulate its own depth of thinking. We treat reasoning as a spectrum, ranging from fast heuristics to deep chain-of-thought to precise tool-like solving, and we train a neural meta-controller to decide which mode to use for each task. By optimizing the …
Continue reading How to Build a Meta-Cognitive AI Agent That Dynamically Adjusts Its Own Reasoning Depth for Efficient Problem Solving
AI Interview Series #4: Transformers vs Mixture of Experts (MoE)

Question: MoE models contain far more parameters than Transformers, yet they can run faster at inference. How is that possible? Difference between Transformers & Mixture of Experts (MoE) Transformers and Mixture of Experts (MoE) models share the same backbone architecture—self-attention layers followed by feed-forward layers—but they differ fundamentally in how …
Continue reading AI Interview Series #4: Transformers vs Mixture of Experts (MoE)
Apple Researchers Release CLaRa: A Continuous Latent Reasoning Framework for Compression‑Native RAG with 16x–128x Semantic Document Compression

How do you keep RAG systems accurate and efficient when every query tries to stuff thousands of tokens into the context window and the retriever and generator are still optimized as 2 separate, disconnected systems? A team of researchers from Apple and University of Edinburgh released CLaRa, Continuous Latent Reasoning, (CLaRa-7B-Base, CLaRa-7B-Instruct and CLaRa-7B-E2E) a …
Continue reading Apple Researchers Release CLaRa: A Continuous Latent Reasoning Framework for Compression‑Native RAG with 16x–128x Semantic Document Compression
How to Design a Fully Local Multi-Agent Orchestration System Using TinyLlama for Intelligent Task Decomposition and Autonomous Collaboration

In this tutorial, we explore how we can orchestrate a team of specialized AI agents locally using an efficient manager-agent architecture powered by TinyLlama. We walk through how we build structured task decomposition, inter-agent collaboration, and autonomous reasoning loops without relying on any external APIs. By running everything directly through the transformers library, we create …
Continue reading How to Design a Fully Local Multi-Agent Orchestration System Using TinyLlama for Intelligent Task Decomposition and Autonomous Collaboration